
Author: Manikanta Kuna
Website: www.Manikantakuna.com
What Are GenAI System Modules?
A Generative AI model like GPT isn’t just one big neural network — it is a pipeline of multiple intelligent components working together:
| Module | Purpose |
|---|---|
| Tokenizer | Converts text → numeric tokens |
| Embeddings | Converts tokens → vector meaning |
| Neural Network (Transformer) | Thinking & reasoning |
| Attention | Understanding relationships between tokens |
| RAG / Vector DBs | Knowledge retrieval from external memory |
| Decoding | Convert predicted tokens → readable text |
| RLHF | Make outputs safe, helpful & aligned |
Let’s break each part down 👇
Tokenizers — Breaking Language into Pieces
📌 AI models do not understand words directly.
Text → split into tokens (words, subwords, characters)
Example:
Sentence:
“Generative AI is powerful.”
Tokenized:["Gener", "ative", " AI", " is", " powerful", "."]
Why important?
✔ Reduces vocabulary size
✔ Helps model understand rare words
✔ Efficient training
Popular tokenizers:
- Byte Pair Encoding (BPE)
- WordPiece
- SentencePiece
- Tiktoken (OpenAI)
Word & Sentence Embeddings Meaning in Numbers
Each token is mapped into a vector in multidimensional space.
Example intuition:
- “King” and “Queen” are close vectors
- “King” – “Man” + “Woman” ≈ “Queen”
Embedding types:
- Static: Word2Vec, GloVe
- Dynamic (context-aware): Transformer embeddings
This is how models understand semantic meaning.
Attention & Self-Attention — The Real Intelligence
Transformers introduced Self-Attention:
The model focuses on important tokens within a sentence
Sentence:
“She went to the bank to deposit money.”
Attention reveals:
- “bank” → “deposit money”
- Not “bank” → “river”
Benefits:
✔ Understands long-context
✔ Parallel processing → faster
✔ Core logic of all LLMs today
Multi-Head Attention = multiple perspectives at once
Decoder & Generation Creating Token-by-Token Output
LLMs are Autoregressive:
Predict the next token based on previous tokens:
“The weather is…” → “sunny” → period → finish
Common decoding strategies:
| Strategy | Behavior |
|---|---|
| Greedy search | Picks best next token (boring) |
| Beam search | Multiple paths (accurate) |
| Sampling (Top-P, Temperature) | Creative, diverse |
| Mixture | Balanced outputs |
This module determines creativity vs. correctness.
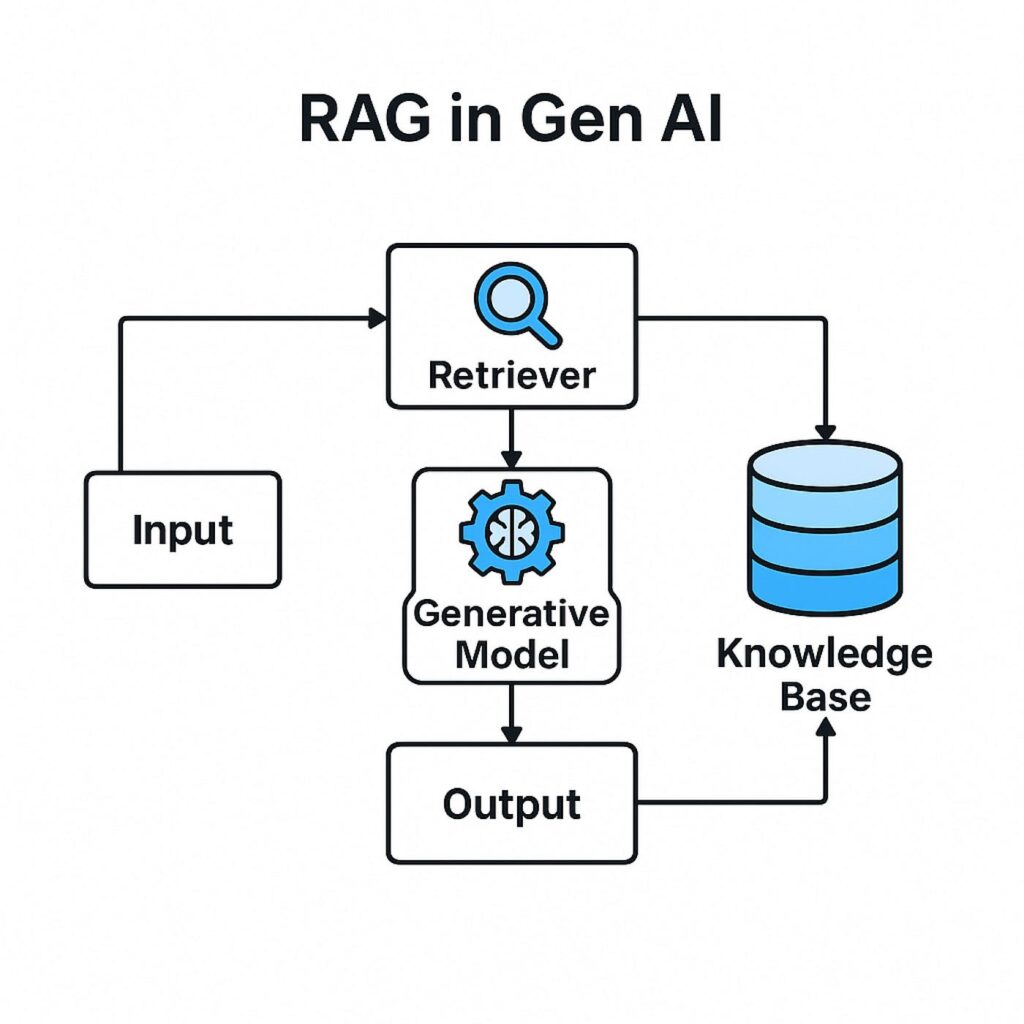
RAG (Retrieval Augmented Generation) AI with Real Knowledge
Problem:
Models forget things after training (no real-time knowledge)
Solution:
Retrieve relevant information from a Vector Database before generating an answer
Flow:
1️⃣ Convert user question → embeddings
2️⃣ Search in vector DB
3️⃣ Send retrieved knowledge + prompt to model
4️⃣ Model produces structured output
Used in:
- Enterprise AI
- Chatbots with company data
- Private knowledge assistants
RAG = AI + Memory
Vector Databases — Brain Memory Storage
Neurons store embeddings in high-dimensional format.
Popular vector DBs:
- Pinecone
- FAISS
- Milvus
- Weaviate
- ChromaDB
Optimized for:
✔ Fast search
✔ Semantic similarity
✔ Scalability with billions of vectors
➡️ Deep dive coming in Blog #4
RLHF — Teaching AI Human Values
LLMs trained only on data are:
- Raw
- Unsafe
- Biased
So humans give feedback:
RLHF = Reinforcement Learning from Human Feedback
Process:
1️⃣ Humans label good vs bad responses
2️⃣ AI learns the preferred behavior
3️⃣ Safer + aligned responses
This is how ChatGPT stopped saying harmful/wrong stuff.
Optional Modules in Production Systems
| Module | Benefit |
|---|---|
| Agent Orchestration | Multi-step automation |
| Tools / APIs Access | Browsing, calculator, code execution |
| Memory Store | Personalized user experience |
| Guardrails | Safety rules, filtering |
These convert LLM → Autonomous AI Agents
Putting It All Together
GenAI is not just a model — it is an ecosystem of components working together to understand, reason, and generate knowledge.
Pipeline summary:
Token → Embedding → Attention → Thinking → RAG Memory → Decoding → RLHF Safety ✔